Facebook Has Good MANRS. Mistakes Still Happen.
A colleague calls his dad every afternoon, usually via WhatsApp. I bet you can see where this is going: Monday, he couldn’t reach him and got worried about what he was doing, where he was, and most importantly, if he’d be able to order dinner online from his favorite restaurant like he does every Monday. It reminded me how many people rely on the Internet to do so much, and why the Internet Society believes that the Internet is a lifeline.
As you undoubtedly heard, on Monday Facebook had a large outage lasting about six hours affecting Facebook, Instagram, WhatsApp, and other Facebook properties. As in the aftermath of any large-scale issue, Internet rumors ran rampant about what happened and why. Let’s take a moment to discuss what we know and put this in some context.
What Happened?
Cloudflare offered a good preliminary technical analysis, and later Facebook issued its own explanation.
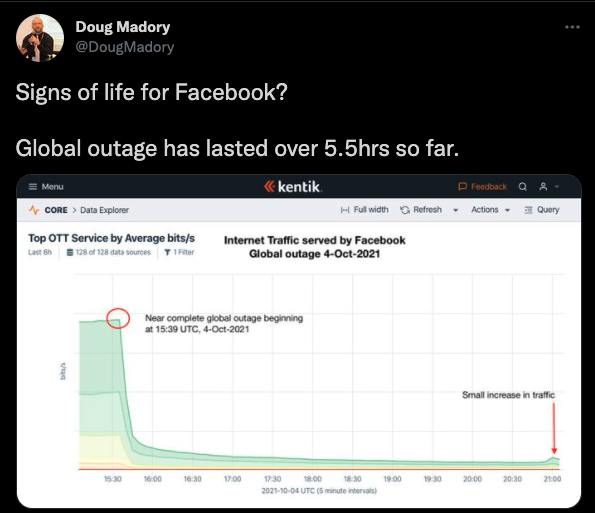
Around 15:40 UTC, AS32934 (Facebook) started withdrawing some BGP routes, specifically those that host its DNS. Facebook’s DNS servers, which provide clients with information on how to find all of Facebook’s resource records like “facebook.com”, “instagram.com”, and “whatsapp.com” became unreachable. As Cloudflare said, “Their DNS names stopped resolving, and their infrastructure IPs were unreachable. It was as if someone had “pulled the cables” from their data centers all at once and disconnected them from the Internet.” In BGP, the withdrawal mechanism suggests to a BGP speaker that it no longer has a viable path to a given prefix and it should announce “withdrawal” to all its neighbors.


The RIPE Stat BGP Update Activity for AS32934 then shows a significant amount of BGP updates starting from 15:40 UTC. AS32934 normally announces around 150 IPv4 routes and 280 IPv6 routes, but not all of them were withdrawn during this outage.

The following video using BGPlay @ massimocandela.com shows when the IP address range 185.89.218.0/24 was withdrawn and re-announced, causing approximately 5 hours and 18 minutes worth of outages. (If you want understand how BGPlay works, RIPE Labs published a very informative post here.)
Doug Madory from Kentik also shared similar statistics suggesting a 5.5-hour outage.
Later, the Facebook engineering team published the reason for the outage on their website:

This Was a Big Outage
On today’s Internet, there are a few very large content platforms like Facebook. If they experience a service disruption, it quickly becomes headline news because it impacts the lives of countless people who rely on such services to conduct business, connect with loved ones, and more. In addition, sometimes outages at large platforms can affect hundreds of networks relying on them, like when Fastly and Akamai had network outages earlier this year.
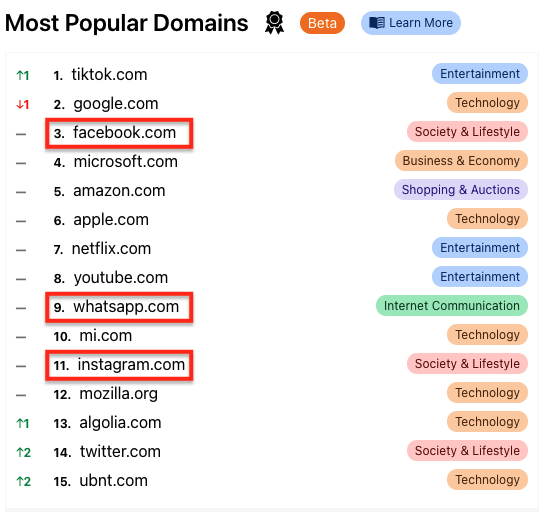
In this case, when three major websites and social media platforms – ranked in the top 15 sites per Cloudflare Radar – go down, it becomes the biggest news of the day. Facebook alone has 1.9 billion (on average for June 2021) daily active users, so imagine the impact of an outage of all three platforms combined.
This Was Not An Attack
In the end, humans run networks, and humans make mistakes. Facebook’s announcement stated a bug in an audit tool sent everything haywire.
We see routing security incidents like BGP leaks and BGP hijacks daily, but this time it appears to most likely be a genuine configuration mistake. There is no evidence to suggest this was a result of Facebook, a MANRS participant, failing to implement the MANRS actions.
Open standards are a cornerstone of the Internet. They are key to allowing devices, services, and applications to work together across a wide and dispersed network of networks. In this case, DNS and BGP behaved exactly as designed. This was not a DNS failure or a BGP failure. This was a simple mistake.
The Internet is Complicated
The Internet is a huge and complex ecosystem. We think of it as a monolith because of the protocols behind it, but what we’re seeing every day is more than 70,000 independent networks working together, relying on each other to exchange information and move data around the world.
The Internet is successful in large part due to its unique model: shared global ownership, open standards development, and freely accessible processes for technology and policy development. The Internet’s unprecedented success continues to thrive because the Internet model is open, transparent, and collaborative.
We Can Work Together to Improve Routing Security
One of the great things of the Internet is that everyone can help it grow and be more secure. MANRS is a community-led initiative to improve the global routing security system. Today, MANRS offers four different programs for organizations operating different parts of the Internet: network operators, Internet exchange points, CDN and cloud providers, and equipment vendors. You can join us today, and you can also be part of the new Steering Committee – nominations are open!
Many people have just learned about Border Gateway Protocol (BGP) after this incident. If that’s you, welcome! We have a series of five simple posts on routing, routing security, and MANRS to help you get started. We also have four documents with specific recommendations for policymakers, IT executives, enterprises, and CSIRTs. Please share the MANRS Primers with people you think need to see them.
There are several routes to reach other devices over the Internet. There are also several routes to be part of a like-minded community actively working to strengthen the Internet by securing the global routing system. The choice is yours.
Leave a Comment